Ein Searchengine Setup mit Solr und Nutch
Ich wollte herausfinden ob und wie man mit Opensource Produkten eine Suchmaschine für eine Webseite aufbauen kann. Bei diesem Thema kommt man schnell auf Solr. Damit man dieser Suchengine auch etwas zum Finden geben kann braucht man einen Webcrawler der die gewünschten Webseiten durchsucht und sie Solr vorwirft. Hier scheint Nutch das Werkzeug der Wahl zu sein.
Basis für meinen ersten Test war diese zwei Tutorials
Der Ablauf ist grob:
1. Installation und Konfiguration des Web Crawlers für die gewünschte Web Seite
2. Installation von Solr und Konfiguration einer Collection
3. Aufruf des Webcrawler so dass dieser seine Ergebnisse Solr übergibt.
Zuerst der Download und das Auspacken von Nutch
wget http://mirrors.ae-online.de/apache/nutch/1.7/apache-nutch-1.7-bin.tar.gz tar xzvf apache-nutch-1.7-bin.tar.gz
Dann dien Basiskonfigurationsschritte - Wie nenne ich meinen Webcrawler und welche URLs oder Webseite möchte ich durchsuchen?
cd apache-nutch-1.7
vi conf/nutch-site.xml
.....
<configuration>
<property>
<name>http.agent.name</name>
<value>HB Nutch Spider</value>
</property>
</configuration>
.......
mkdir urls
vi urls/seed.txt
/
vi conf/regex-urlfilter.txt
+^http://([a-z0-9]*\.)*www.hagen-bauer.de/
Das war der Webcrawler. Jetzt die Suchengine Solr
wget http://mirror.serversupportforum.de/apache/lucene/solr/4.6.0/solr-4.6.0.tgz
tar xzvf solr-4.6.0.tgz
mv solr-4.6.0/example/solr/collection1 solr-4.6.0/example/solr/hagen-bauer
vi solr-4.6.0/example/solr/hagen-bauer/core.properties # Den Namen ändern
java -jar start.jar
0 [main] INFO org.eclipse.jetty.server.Server - jetty-8.1.10.v20130312
90 [main] INFO org.eclipse.jetty.deploy.providers.ScanningAppProvider - Deployment monitor /root/suchen/solr-4.6.0/example/contexts at interval 0
113 [main] INFO org.eclipse.jetty.deploy.DeploymentManager - Deployable added: /root/suchen/solr-4.6.0/example/contexts/solr-jetty-context.xml
Dann kann man die admin console auf der dieser Addresse http://yourserver:8983/solr/#/ aufsuchen können 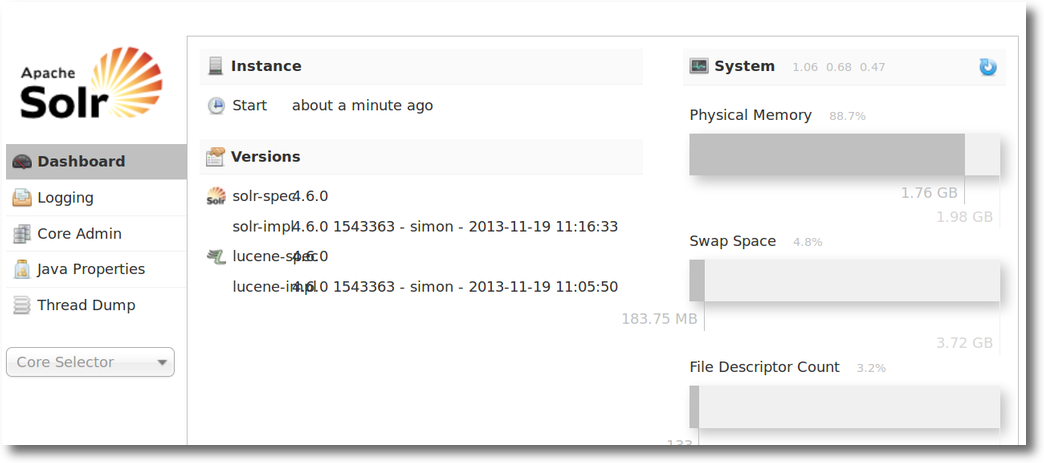 Dann der erste Crawl aufruf
Dann der erste Crawl aufruf
export JAVA_HOME=$(readlink -f /usr/bin/java | sed "s:bin/java::") bin/nutch crawl urls -depth 2 -topN 15 -solr http://127.0.0.1:8983/solr/hagen-bauer-de/ Indexer: finished at 2013-12-26 17:46:55, elapsed: 00:00:09 SolrDeleteDuplicates: starting at 2013-12-26 17:46:55 SolrDeleteDuplicates: Solr url: http://127.0.0.1:8983/solr/hagen-bauer-de/ SolrDeleteDuplicates: finished at 2013-12-26 17:46:56, elapsed: 00:00:01 crawl finished: crawl-20131226174450
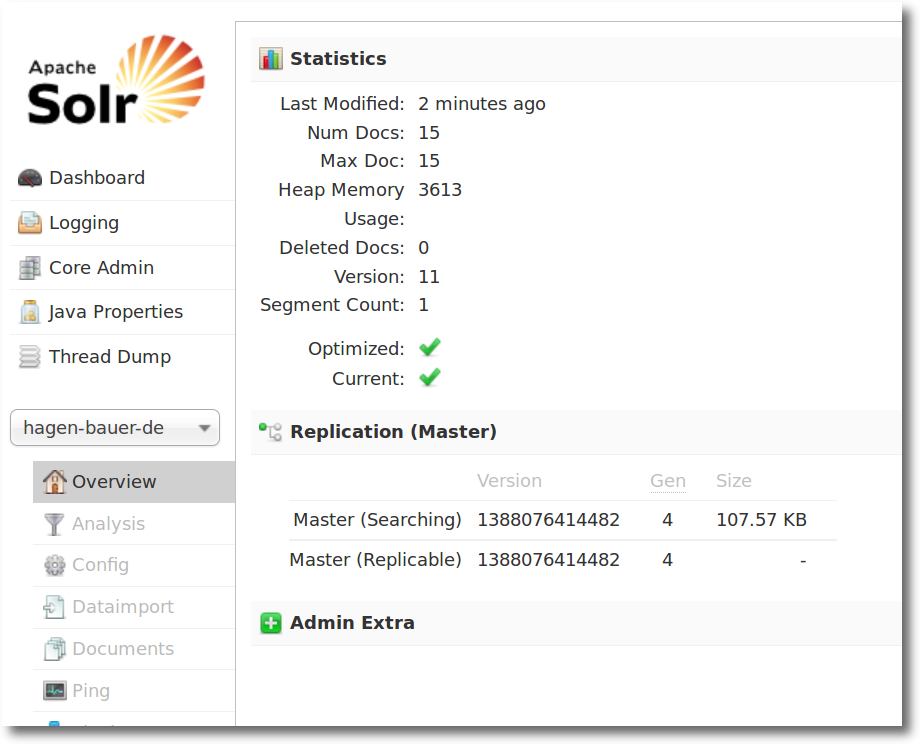 Ein einfaches Suchinterface kann man an dieser Stelle aufrufen und erste Suchstichproben absetzten
Ein einfaches Suchinterface kann man an dieser Stelle aufrufen und erste Suchstichproben absetzten
http://yourserver:8983/solr/hagen-bauer-de/browse
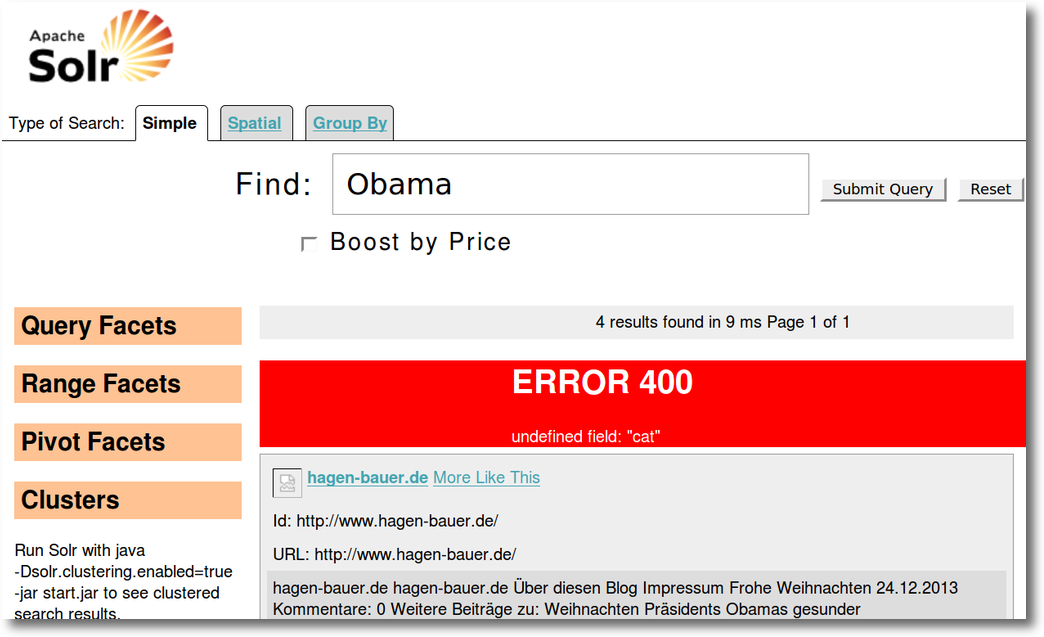 Das Ergebniss ist zwar noch nicht "schön und fertig" aber zumindestens steht der Webcrawler und man findet etwas. Wie man das ganze jetzt von Aussehen auf seine Wünsche anpasst ist die nächste Aufgabe
Das Ergebniss ist zwar noch nicht "schön und fertig" aber zumindestens steht der Webcrawler und man findet etwas. Wie man das ganze jetzt von Aussehen auf seine Wünsche anpasst ist die nächste Aufgabe