Movabletype mit Solr indexieren
An dieser Stelle hatte ich beschrieben, wie man die Suchmaschine Solr mithilfe des Webcrawler Nutch füttern kann. Das funktioniert auch recht einfach - hat nur einige Nachteile. Zum einen bekommt man auch einige Seiten mit in den Index die man eigentlich nicht haben möchte (z.B. Monatsarchive) zum anderen ist es nicht ganz so einfach an die Metadaten heran zu kommen.
Wenn man direkt auf die SQL Datenbank zugreifen kann bietet Solr auch die Möglichkeit diese Daten direkt aus der Datenbank auszulesen. Das ist zum einen schneller und man hat direkt die Rohdaten.
Dieses Dokument beschreibt die Schritte zum Einbinden meines Blogs auf Basis Movabletype.
Die Installation habe ich in den folgenden Schritten hinbekommen
- Installation des Datenbanktreibers
- Erstellen einer "Schnittstellenkonfigurationsbeschreibung
- Definition der Felder in Solr
- Wie soll das in Solr importiert werden
Datenbanktreiber installieren
Download der Treiber von hier, auspacken und an die richtige Stelle verschieben
cd /solr-4.6.0 mkdir mysqldriver mysqldriver/ mv /tmp/mysql-connector-java-5.1.28.tar.gz . tar xzvf mysql-connector-java-5.1.28.tar.gz mv mysql-connector-java-5.1.28/mysql-connector-java-5.1.28-bin.jar example/lib/ rm -r mysql-connector-java-5.1.28 rm mysql-connector-java-5.1.28.tar.gz
Jetzt müssen wir Solr noch sagen von welcher Stelle der Treiber (und noch einen anderen den wir später brauchen) einbinden soll.
cd /example/solr/hagen-bauer/
vi conf/solrconfig.xml
<lib dir="../../../dist/" regex="solr-dataimporthandler-.*\.jar" />
<lib dir="./lib" />Schnittstellenbeschreibung erstellen.
Wir erstellen für den Blog eine Konfigurationsdatei
vi conf/blog-data-config.xml
<dataConfig>
<dataSource name="mysql" driver="com.mysql.jdbc.Driver" url="jdbc:mysql://localhost/mt" user="mt_admin" password="geheim" batchSize="-1" />
<document name="content">
<entity name="entries" transformer="TemplateTransformer, HTMLStripTransformer"
query=" select entry_id,entry_title,entry_basename, entry_text from mt_entry where entry_blog_id=4 and entry_status=2; ">
<field column="ENTRY_ID" name="entry_id" />
<field column="ENTRY_TITLE" name="entry_title" />
<field column="ENTRY_BASENAME" template="/archive/${entries.entry_id}.html" />
<field column="ENTRY_TEXT" name="entry_text" stripHTML="true" />
<entity name="emtymetadata"
query="SELECT tag_name FROM mt_objecttag, mt_entry, mt_tag WHERE objecttag_object_id = entry_id AND ENTRY_ID = '${entries.entry_id}' AND objecttag_tag_id = tag_id ">
<field column="tag_name" name="entry_tags"/>
</entity>
</entity>
</document>
</dataConfig>Was soll uns das sagen:
- Datenquelle mit den Informationen zu der Datenbank
- eine Entity Definition die Dokumente anlegt und den Inhalt dazu mit einem bestimmten SQL Query aus der Datenbank hohlt.
- Welche Felder möchte ich haben?
- Für ein Bestimmtes Feld möchte ich noch etwas Text hinzufügen damit ich die URL bekomme.
- Eine weitere SQL Abfrage die mir aus anderen Tabellen die Tags hohlt
(Offen: leider klappt das mit dem stripHTML noch nicht)
Felddefinition in Solr
Felder werden in Solr in einer bestimmten Datei definiert.
edit schemal.xml <uniqueKey>entry_id</uniqueKey> <field name="entry_id" type="string" indexed="true" stored="true" required="true"/> <field name="entry_title" type="text_de" indexed="true" stored="true" required="true"/> <field name="entry_basename" type="string" indexed="true" stored="true" required="true"/> <field name="entry_text" type="text_de" indexed="true" stored="true" required="true"/> <field name="entry_tags" type="string" indexed="true" stored="true" required="false" multiValued="true"/>
<field name="text" type="string" indexed="true" stored="true" required="false"/>
<field name="alltext" type="text_de" indexed="true" stored="false" multiValued="true"/>
<copyField source="entry_*" dest="alltext"/>
Importroutine für Solr Admin
Damit der Import aus der administrativen Oberfläche oder per URL angestossen werden kann brauchen wir noch folgende Definition:
vi solrconfig.xml <requestHandler name="/dataimport" class="org.apache.solr.handler.dataimport.DataImportHandler">
<lst name="defaults">
<str name="config">/root/suchen/solr-4.6.0/example/solr/hagen-bauer/conf/blog-data-config.xml</str>
</lst>
</requestHandler>
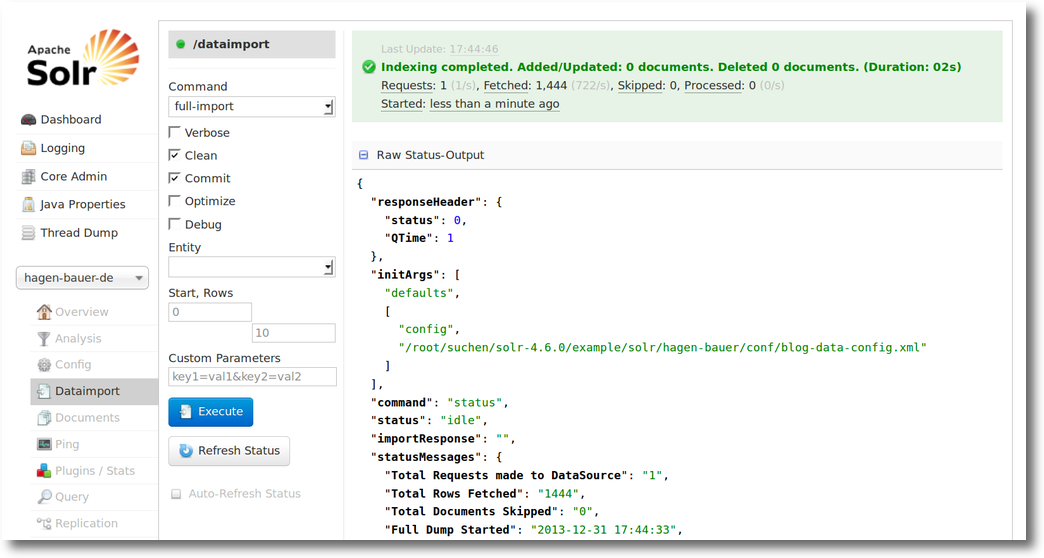
Geht man jetzt mit einerm Browser zu dieser Seite
http://yourserver:8983/solr/#/hagen-bauer-de/dataimport//dataimport
könnte ein erfolgreicher Import so aussehen:
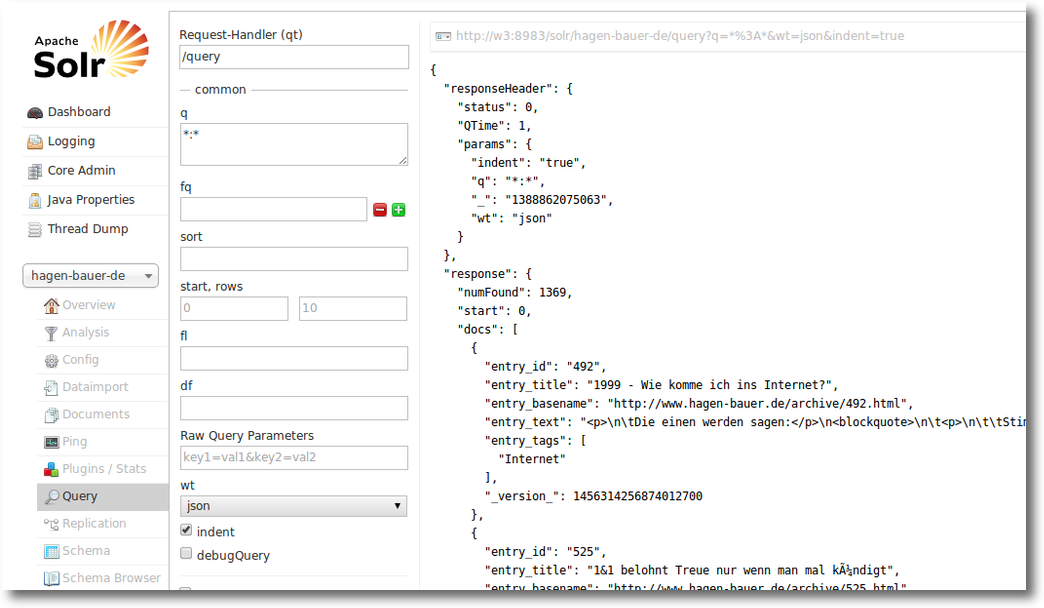
Und unter der Addresse
http://yourserver:8983/solr/#/hagen-bauer-de/query
kann man dann auch suchen: